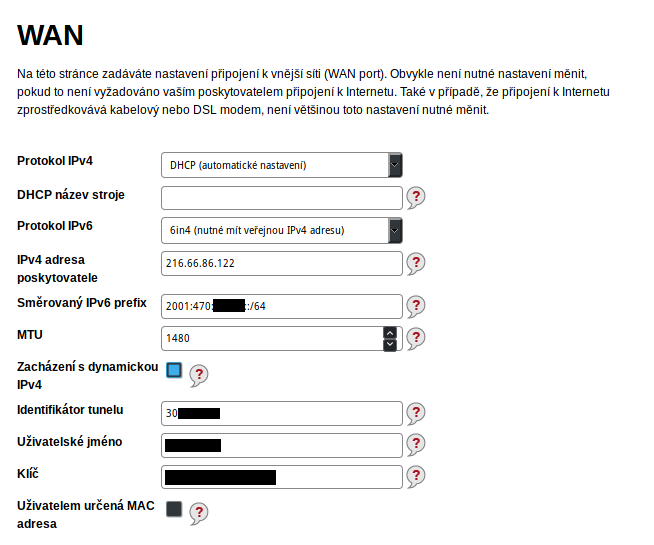
Quite complicated, but I did it a little differently. I tried the same curl command on my laptop and then directly from turris. It works properly there, so issue is between router and laptop. Probably not wifi issue, as my CentOS computer is connected via cable and currently I’m connected via OpenVPN.
Directly from Turris
marian@turris ~ $ time curl -6 https://openstreetmap.cz >/dev/null
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 32959 0 32959 0 0 51903 0 --:--:-- --:--:-- --:--:-- 56052
real 0m 0.66s
user 0m 0.03s
sys 0m 0.00s
turris ~ # traceroute6 openstreetmap.cz
traceroute to openstreetmap.cz (2001:15e8:110:2337::1) from 2001:470:6f:7b6::1, 30 hops max, 16 byte packets
1 tunnel306502.tunnel.tserv27.prg1.ipv6.he.net (2001:470:6e:7b6::1) 12.814 ms 12.165 ms 12.165 ms
2 10ge2-1.core1.prg1.he.net (2001:470:0:221::1) 8.175 ms 8.052 ms 7.894 ms
3 nix1-ipv6.forpsi.net (2001:7f8:14::53:1) 17.636 ms 15.366 ms 14.757 ms
4 2001:15e8:0:1::1 (2001:15e8:0:1::1) 17.401 ms 12.062 ms 13.125 ms
5 osm.kasparkovi.net (2001:15e8:110:2337::1) 13.573 ms !S 82.478 ms !S 11.5 ms !S
From laptop (currently connected via VPN)
[22:01:01 marian@nbmkyral ~]$ time curl -6 https://openstreetmap.cz >/dev/null
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 32982 0 32982 0 0 44 0 --:--:-- 0:12:19 --:--:-- 0
curl: (56) OpenSSL SSL_read: SSL_ERROR_SYSCALL, errno 110
real 12m19,279s
user 0m0,085s
sys 0m0,020s
[22:45:30 root@nbmkyral ~]# traceroute6 openstreetmap.cz
traceroute to openstreetmap.cz (2001:15e8:110:2337::1), 30 hops max, 80 byte packets
1 2001:470:6f:7b6::1 (2001:470:6f:7b6::1) 14.015 ms 66.435 ms 66.440 ms
2 tunnel306502.tunnel.tserv27.prg1.ipv6.he.net (2001:470:6e:7b6::1) 66.438 ms 66.435 ms *
3 * * *
4 * * *
5 2001:15e8:0:3::2 (2001:15e8:0:3::2) 66.373 ms 2001:15e8:0:1::1 (2001:15e8:0:1::1) 66.375 ms 2001:15e8:0:3::2 (2001:15e8:0:3::2) 66.362 ms
6 osm.kasparkovi.net (2001:15e8:110:2337::1) 66.343 ms !X 23.275 ms !X 23.457 ms !X
Configuration
tap0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.221 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fd39:c274:6a4a:0:c4e2:XXXXX prefixlen 64 scopeid 0x0<global>
inet6 2001:470:6f:7b6:c4e2:XXXXX prefixlen 64 scopeid 0x0<global>
inet6 fe80::c4e2:XXXXX prefixlen 64 scopeid 0x20<link>
ether c6:e2:00:12:c0:65 txqueuelen 100 (Ethernet)
RX packets 1029763 bytes 1340567939 (1.2 GiB)
RX errors 0 dropped 2 overruns 0 frame 0
TX packets 641337 bytes 61676599 (58.8 MiB)
TX errors 0 dropped 315 overruns 0 carrier 0 collisions 0
Any idea, what to check now?
UPDATE: just tested debian in LXC - the same issue…
marian@homeassistant:~$ time curl -6 https://openstreetmap.cz >/dev/null
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 25322 0 25322 0 0 101 0 --:--:-- 0:04:08 --:--:-- 0^C
real 4m9,380s
user 0m0,176s
sys 0m0,037s
marian@homeassistant:~$ time curl -4 https://openstreetmap.cz >/dev/null
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 32956 0 32956 0 0 99k 0 --:--:-- --:--:-- --:--:-- 99k
real 0m0,415s
user 0m0,115s
sys 0m0,022s