To connect two Omnias (site-to-site) you can just use masquerading (for the WireGuard interface) and putting the relevant subnets into the allowed IP configuration for the two “peers” (the two Omnias).
This is similar to the configuration I have set up. It assumes that the WireGuard interface is wg0.
# Peer 1
config wireguard_wg0
option public_key 'public_key_of_peer_2'
list allowed_ips 'VPN_IP_OF_PEER2/32'
# example subnet served by peer 2
list allowed_ips '192.168.40.0/24'
option route_allowed_ips '1'
option endpoint_host 'endpoint_ip'
And for peer 2
# Peer 2
config wireguard_wg0
option public_key 'public_key_of_peer_1'
list allowed_ips 'VPN_IP_OF_PEER1/32'
# example subnet served by peer 1
list allowed_ips '192.168.30.0/24'
option route_allowed_ips '1'
option endpoint_host 'endpoint_ip'
Of course you need to make sure that the WireGuard interface is properly masqueraded.
Did you ever experience that a connection was not up/working any more after some time?
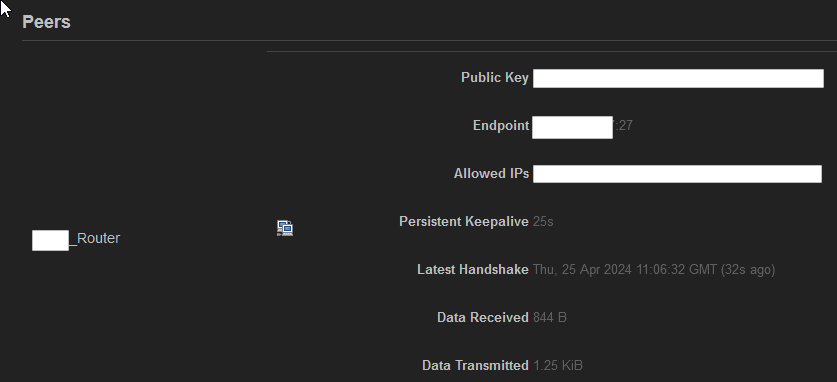
root@TO1:~# wg show
peer: <public key of TO2>
preshared key: (hidden)
endpoint: <public IP TO2 more than 4 days ago>:27
allowed ips: 192.168.3.0/24, 192.168.1.2/32
latest handshake: 4 days, 17 hours, 24 minutes, 48 seconds ago
transfer: 30.95 MiB received, 13.39 MiB sent
persistent keepalive: every 25 seconds
Directly accessing the second TO via mobile WG-app works seamlessly and restarting wg interface on TO1 also restores the wg connection. Is there some sort of log-files one could examine?
the wireguard kernel module is reporting via dmesg and shows in the syslog, hence if the module fails it would show there.
As for the connection it is being managed by netifd and its reports are also showing in syslog, however only events such as up or down. Stale wg connectivity (handshakes) are not reported anywhere in logs though, afaik.
Yes, but only if connectivity to that node was lost, which the stale handshake indicates. Afaik the handshake refreshes every 120 sec.
From what you posted earlier it would appear that wg on the TO2 node became inaccessible to to wg on the TO1 node some 4 days, 17 hours, 22 minutes, 48 seconds earlier (at that time).
Which could be a variety of reason, routing, firewall, physical connectivity.
that would likely have invoked a reload of the firewall and refresh of routing on the TO1 node.
If your node is on TOS3.x then netifd (the network management component) is outdated and buggy and might cause the issue, but that is rather speculative to assume.
That is not true unless you configure it, up to my knowledge. In default wireguard won’t send keep-alive like packets so routers on the way can drop udp connection from tracked ones. Note that where tcp standardize this time in nat, udp does not. This means that real time is up to nat configuration and load and there is no magical constant that works everywhere. In case of my isp it became stable only with 30sec renewal. You have to play with that time.
I got the same persistent keepalive: every 25 seconds as the OP and since ever I use wg the latest handshake does not exceed 120 seconds, unless the connectivity turns stale with the remote node turns stale.
And of course you are correct
A handshake initiation is retried after REKEY_TIMEOUT + jitter ms, if a response has not been received, where jitter is some random value between 0 and 333 ms.
If we have sent a packet to a given peer but have not received a packet after from that peer for (KEEPALIVE + REKEY_TIMEOUT) ms, we initiate a new handshake.
That’s just what I configured - so my case should never happen by design - because if connection is dropped both wg if should try to reestablish connection for ever or until they succeed, right?
Edit: as a addition - both wg if were accessible before I restarted wg if on TO1 (tested with mobile phone), so it shouldn’t be a routing or firewall issue…
From you reported it seems that the nodes lost physical connectivity with each other at some point and it was not re-established.
it is not likely but there could be other factors/apps on the router that could come into play, like I mentioned earlier the buggy netifd on TOS3.x.
Suppose the only way to debug the issue is monitoring the wg connectivity, see if there is a potential pattern if it happens repeatedly. Perhaps you could also
and see whether it makes an impact.
Worst case, if the issue persists, is to run a tcpdump on the wg iface(s). But that should be fine tuned with the options available to tcpdump in order to mitigate the size of the dump when running it unattended over a prolonged period.
I was able to setup Wireguard on TOS3.11.5 as VPN server.
I used the same firewall rules I have for the OpenVPN server.
I’m able to connect to LAN devices and route all traffic through my router WAN using IPv4.
I’m having problem with IPv6.
Client receives IPv6, client can ping LAN devices using IPv6, DNS resolver works on TOS with IPv6 addresses.
But no traffic is forwarded to the WAN.
Did anybody got IPv6 working?
Already set to 1.
I think it may be an issue with my IPv6 configuration.
IPv6 assignment is different than IPv4, and I may need a specific assignment.
I will need to do more reading on that.
I was able to make it work, but I still think it can be done better.
The unique local address (ULA) subnet I used for Wireguard IPv6 is not designed for global IPv6 internet. This ULA subnet doesn’t match the LAN one, not sure if that is better.
I changed my WAN6 setting to request a global IPv6 /60 subnet from my ISP, and I created 2 /64 subnets, one for my LAN (hint=1), and one for my Wireguard interface (hint=2).
Now my Wireguard peers receive 2 IPv6 addresses, one local and one global.
However my ISP may change my global IPv6 range, and they are set as static in my Wireguard settings.
Maybe there is a way to use DHCP inside Wireguard.
Afaik WG does not provide logging facilities on Linux, though it appears that the app for Android does.
This also been discussed here [1]
Since WG leverages UDP sockets those are less probable by port sniffers than TCP sockets. Having such UDP socket listening only on IPv6 makes it virtually improbable by a port sniffer - unless perhaps with the power of quantum computing. However, if a publicly accessible PTR records exists for the IPv6 WG listens on a sniffer would not have to scan the IPv6 address space but the ports only.
Even if a listening UDP socket would be discovered by a port sniffer it would likely take the power of quantum computing to:
attack the cryptography that is implemented by WG, and/or
brute force probe with a private key the access to a WG peer
That said, the WG developer always mentions in release notes
it is not applicable for CVEs.
Meaning that WG has not undergone a thorough testing for potential vulnerabilities. With WG slated to be incorporated in the Linux kernel 5.6 this may change however.
Hi all, do I understand correctly that for each client connecting to WG VPN server running at TO, there needs to be a separate interface (wg0, wg1, …) configured on TO?
With update to 7.0 somehow my “road-warrior”-setup does not work anymore. To be honest - I haven’t ever tested that connection after I got my fibre-access (before that on IPv4 everything worked flawlessly). So this may be caused by me getting IPv6.
This firewall+wireguard combination at least allows me to connect via internet to another router (even though the access to the internal networks fail - I will troubleshoot that later):
I then imported the config via QR-code to the android (13) wireguard app and started the connection. When looking into the log, it says repeatedly every five seconds starting handshake initiation. Any idea how to troubleshoot that?