Mmmh, RFC6333 phrases this as “A DS-Lite CPE SHOULD NOT operate a NAT function between an internal interface and a B4 interface, as the NAT function will be performed by the AFTR in the service provider’s network. This will avoid accidentally operating in a double-NAT environment.”
So you are right that the ds-lite design does not want NAT there, but I maintain that this is not the same as a hard requirement (which in IETF lingo would be either a MUST or MUST NOT), I also agree that this is getting off-topic fast, so I concede your point.
Sorry for my delay.
Even after half an hour I am loosing IPv6.
Refresh the WAN interface than it is back.
I have try to play with the LCP Echo parameters but the Effect is the same.
From mybpointbif you nothing will fix the issue and I can’ t spend so many time to fix the issue and I don’ t want to stress your support here.
Maybe the failure is in another area …
I have used a FritzBox before and there was a setting from the ISP the IPv6 is Unique by the FB (I don’t know exactly der wording). Maybe the ISP has the problem but I am sure they provides IPv6.
What is the affect when IPv6 is not working?
In the moment I don’t use VPN connection and IPv4 is still activ.
Is there any risk?
Sure, later must be work. Maybe with the next update.
Otherwise I must go back to the FritzBox or another router. Nothing what I want to do 
These come only into play for the ppp-tunnel, unless the ppp link comes and goes changing these parameters should not effect the IPv6 side of things, but you should get nice and normal PPPoE reconnects.
This is a bit curious since the ISP provides the IPv6 via DHCPv6 and it is unclear from the logs why netifd sees it fit to disconnect the wan_6 interface. Debugging would require an investment in time/effort.
Unless mistaken your node is on TOS4.x, which is stale in regards to code development for some time. TOS5.x may not exhibit the issue.
- IPv6 upstream (WAN) connectivity not working, instead traffic will be IPv4 only.
- slight delay in WAN connectivity caused by inital IPv6 connectivity attempts then falling back to IPv4
- but real problem that the pppoe session gets restarted and that will cause intermittent interruptions in WAN connectivity (also IPv4)
There might be however still a misconfiguration on the ISP back-end such as been observed here PPPoE disconnects every few hours - Network and Wireless Configuration - OpenWrt Forum
Unfortunately however
and therefore not due to arrive in TOS for another couple of months.
Makes sense to flash the TO with the latest OS 5.xx?
It is stable enough for the daily work?
Here the config from the FB before:
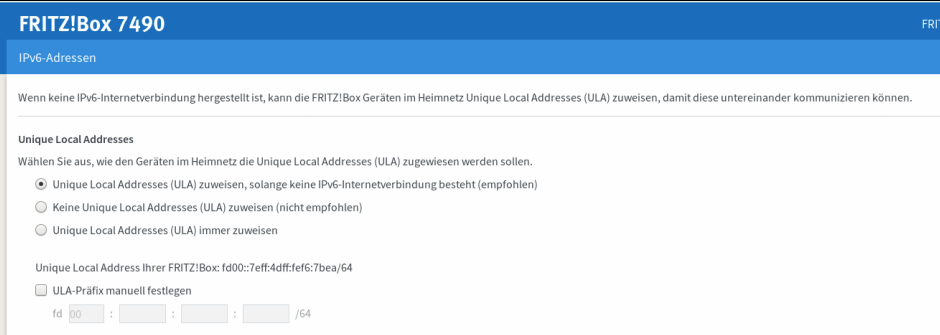
Allocate Unique local adress if no IPv6 internet connection existing (Translation).
Maybe here is also a fault?
With the FB IPv6 was working!
If the IPv6 function not working than I have a problem what I have understood.
Than I need an alternative solution.
What is strange and I don`t understand these: In the LuCi UI I see for WAN an IPv6 address.
When IPv6 is not working why I have this address?
No need to flash the router, with TOS4.x = HBS branch (as of today) just switch the branch to HBT. To move back and forth between the branches schnapps rollback can be used.
Is unrelated - ULA IPv6 address space is sort of the equivalent to the IPv4 private address space.
You can check the router’s own ULAs assigned with ip a - look for the inet6 fd30:... entries.
On the WAN side or the LAN side? For LAN IPv6 connectivity the ULA address space works independently from the WAN’s GUA address space and any intermittent interruption on the WAN does (should) not cause any issue on LAN traffic.
The the interruption period in WAN connectivity (from your last log) lasts from 07:28:09 to 07:28:22 and LuCI does not refresh its UI every second, you just may not catch the interruption on LuCI (assuming the auto refresh in LuCI is enabled in the first place, if not then there would no status change of the interfaces at all).
I have now switch to the HBT brunch.
I will see what is the influence.
For the moment looks OK:
root@turris:~# check_connection Pinging 84.46.104.215 ... OK IPv4 Gateway: OK Pinging 217.31.205.50 ... OK Pinging 198.41.0.4 ... OK Pinging 199.7.83.42 ... OK Pinging 8.8.8.8 ... OK IPv4: OK Pinging fe80::aa9d:21ff:fee1:7f00%pppoe-wan ... OK IPv6 Gateway: OK Pinging 2001:1488:0:3::2 ... OK Pinging 2001:500:3::42 ... OK Pinging 2001:500:2d::d ... OK Pinging 2606:2800:220:6d:26bf:1447:1097:aa7 ... OK IPv6: OK Resolving api.turris.cz ... OK Resolving www.nic.cz ... OK Resolving c.root-servers.net ... OK DNS: OK Resolving www.rhybar.cz ... OK DNSSEC: OK
What is interessting: The Check in Foris is also OK but if I check in an internet side like the following than is IPv6 NOK.
How can be this?
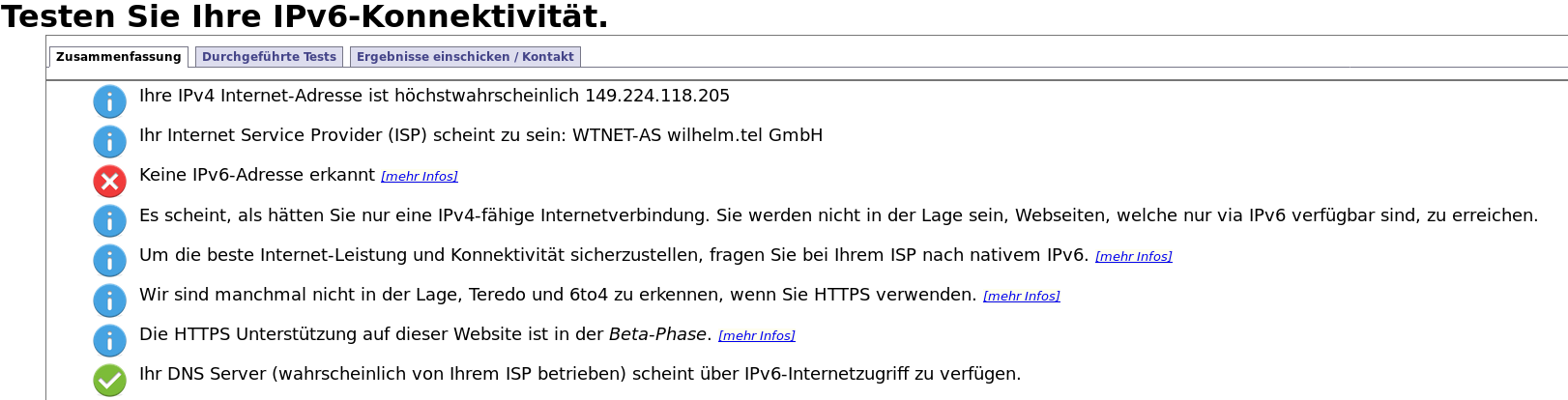
This is different to the HBS brunch.
When the TO test was NOK than was the internet test also NOK and was die internal test OK than was the internet test also OK.
disconnect the client from the router for say 30 sec and then reconnect, should clear the GUA IPv6 lease on the client. Clear the browser cache, run test again.
![]()
Ok, back to the root.
I am loosing again IPv6.

I am desperate!
Too bad and unfortunate.
If it is the ISP’s fault similar to this one
you would have jump through the same debugging hoops.
Alternatively you could stick with WAN IPv4 connectivity only until someone would bother to backport the kernel patch for that issue or wait for kernel 5.4 to arrive in TOS and see then whether it gets sorted.
Else you could,
- see if changing the cable between the router and the FTTH unit helps, if the current cable is an unshielded Cat5 | 5e try with a shielded CAT6 | 6a or Cat 7 | 7a | 8.1 cable instead
- follow the support procedure Support - Turris Documentation and take it up with support, or
- invest time/effort to provide more verbose debugging logs and hope to get it resolved through this community forum.
Next step: I have order new Cat7 cable.
…but I think the issue is on the ISP side.
I have found a thread with the same ISP and the same issue.
https://board.wtnet.de/viewtopic.php?t=9193
Sorry for the German language.
Hi,
Yesterday I had for the whole day IPv6 connectivity.
I don’t know why.
I’ve wrote to my ISP. No answer for the moment.
Today, latest tomorrow I will replace the cable with an Cat 7 double shielded. Temporary I’ve place Cat 6 and I think it’s also protected.
Today the same story like beginning of this thread.
I get the connection and after an half hour I lost IPv6.
It’s not stable.
I think the reason is not the TO router I think it’s depend to the ISP and maybe the the configuration.
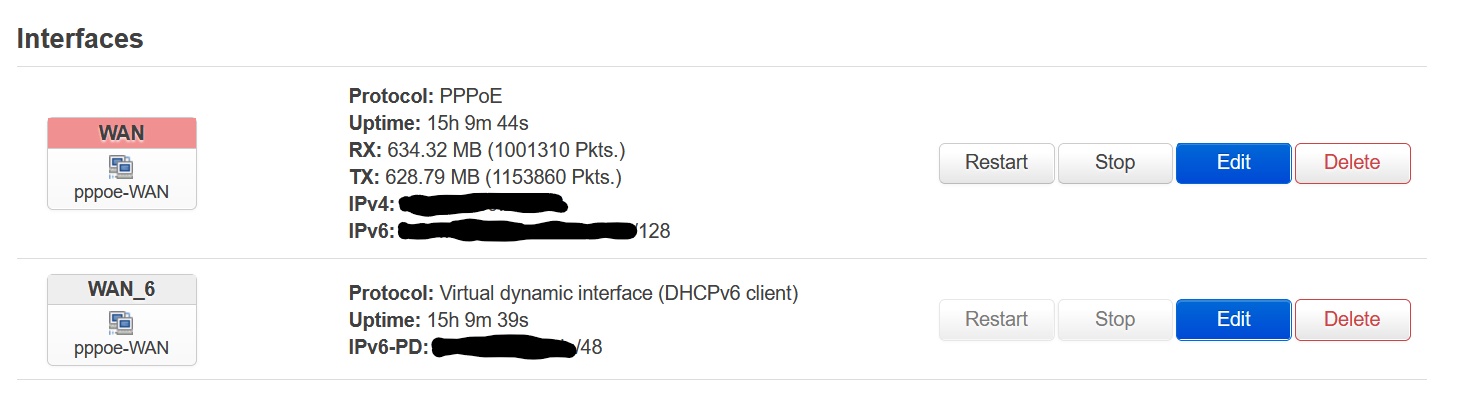
… but there is nothing different between your config and my:
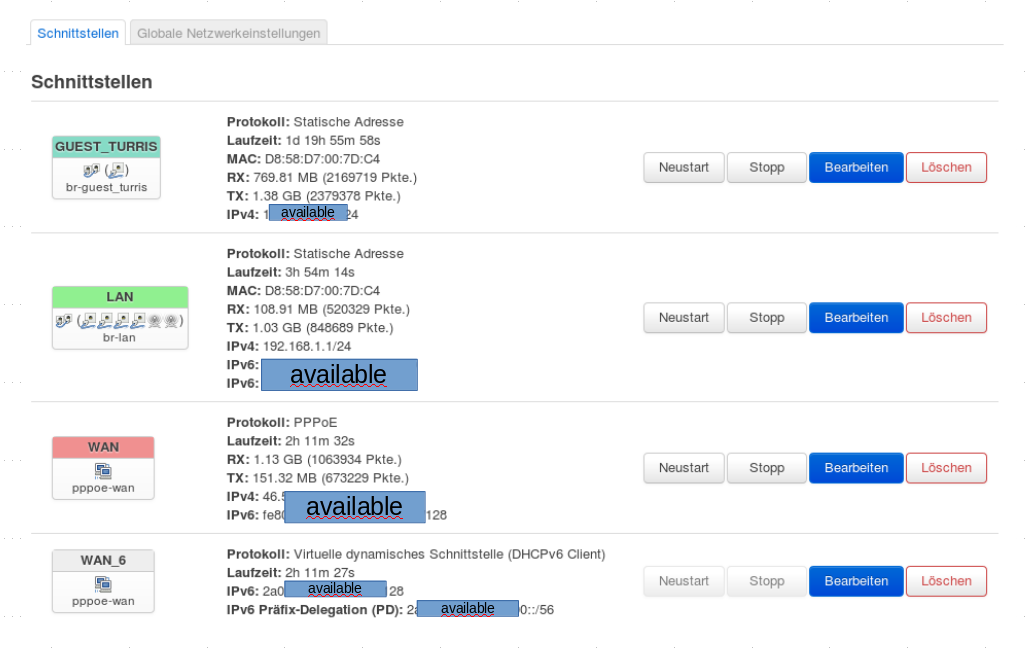
I get a IPv6 adress from the ISP (sure, actually it`s the adress from the first handshake).
The only different is that my TO lost the adress or is not stable, …
…and for WAN_6 is in your overview no IPv6 adress. This is in my one available.
What is now wrong with my internet connection?
I have test another one:
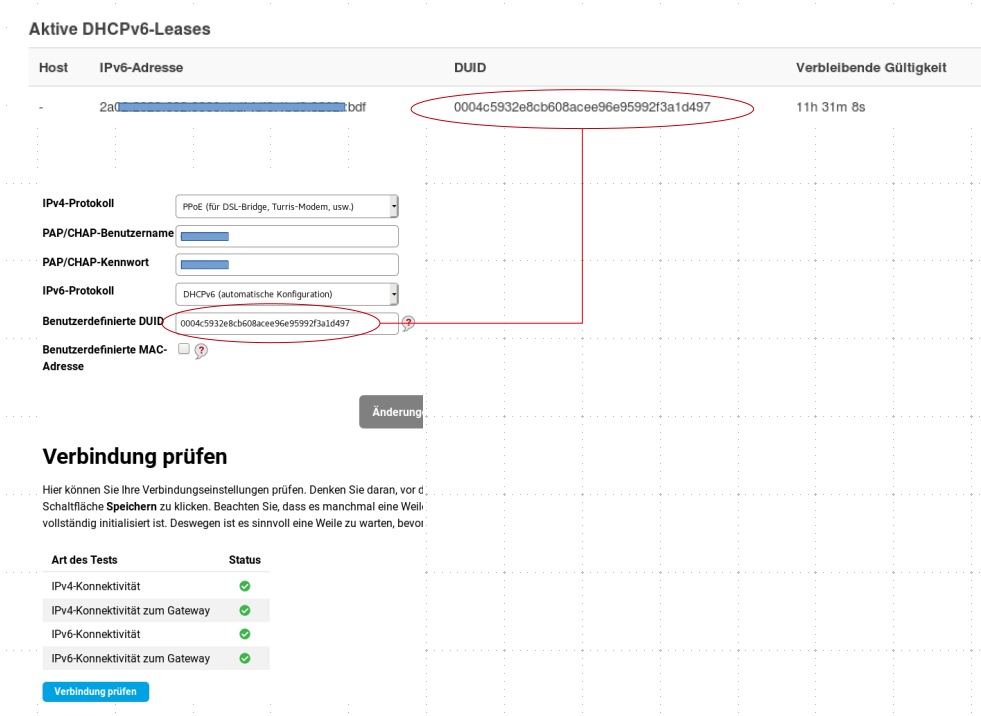
I copy the DUID from the LuCi overview to the Foris configuration for the PPPoE connection.
I will see whats happened. It`s stable and how long.
Maybe only for the rest of the time 11.xxx hour.
OK, last chance before was done. The new cable (Cat 7) has no effect.
It is was I have expected.
I feel that I can configure and try what ever I want. Even it is with any effect!
Only last chance is the support from the ISP.
After that I must buy a new router which can handle IPv6 (maybe in combination with my ISP).
From Turris support I don`t expect the solution (and to slowly. Sorry to say that!). Maybe it is complicate to describe what I have tested. Sure I have wrote to the support.
Thanks a lot for your support and the effort what you have spend!
Maybe later on the Turris has another chance to come back.
Has anybody and recommendation for me regarding a alternative router like DrayTek, MikroTik, … FritxBox will be the last solution.
Comment from 06.06.2020:
Crazy, crazy!
Today in the morning I look in the Foris UI to check the status of IPv6 address and function.
I was so surprised to see it’s available.
OK, I check in addition the interfaces and I was one more time surprised to see the WAN6 interface is back.
The different to before: I can modify thr WAN6 interface. The advanced settings are back, … and WAN6 is only for IPv6 responsible.
Also the assignment for the interfaces is different to yesterday.
WAN6 =“alias from wan”! This was yesterday definitely different. How can it be?
I’ve done nothing!
Self repair function?
This is for me totally crazy, stupid and amazing.
For me it’s unbelievable and I would like to say it’s not acceptable.
I’m so happy (but I’ve say this so often in this thread) it seems to works but I’ve observed in the WAN interface are also something was new configured by self.
I don’t no why and this more critical than it’s not working.
It’s mystic!
uhm…afaik the latest 5.0 has the 'hack’implemented? so, if still trouble, maybe start from scratch? And stay away from foris/reforis. Just stay in Luci. Delete All WAN ( basically the ip4 ) and all the stuff you have been installing to check for errors.
Then just start with ip4, put ipv6 in the ip4 WAN on auto, force link on, and see what happens?
Yes, it have.
What is the behavior in TOS 3?
The first thing what I will do is observe w/o any changes is the router an the OS stable or I’ve tomorrow or in few day’s another situation like it doesn’t work again.
In the meantime I will save the configuration.
There was no update between yesterday and today. Only one failure message one update can’t update (I think regarding the longer disconnection when I route the new Cat 7 cable in the office). I think the updater will try later on to repeat and restart the update again.
For me looks crazy this story.
the hack is implemented and set to 10 seconds. It behaves better, my connections don’t break that often (but they sometimes still do).
just a while ago I encountered the issue:
Jun 21 14:04:58 turris pppd[7140]: LCP terminated by peer
Jun 21 14:04:58 turris pppd[7140]: Connect time 1440.0 minutes.
Jun 21 14:04:58 turris pppd[7140]: Sent 762166809 bytes, received 3902014383 bytes.
...
Jun 21 14:04:58 turris netifd: Interface 'wan' has lost the connection
...
Jun 21 14:04:58 turris pppd[7140]: Exit.
...
Jun 21 14:04:59 turris netifd: wan (15121): ppp: warning: Sleeping for '10' seconds
...
Jun 21 14:05:00 turris netifd: Network device 'eth2' link is down
...
Jun 21 14:05:03 turris netifd: Network device 'eth2' link is up
Jun 21 14:05:03 turris netifd: Interface 'wan' has link connectivity
Jun 21 14:05:03 turris netifd: Interface 'wan' is setting up now
...
Jun 21 14:05:03 turris netifd: wan (15387): ppp: warning: Sleeping for '10' seconds
...
Jun 21 14:05:13 turris pppd[15467]: Plugin rp-pppoe.so loaded.
Jun 21 14:05:13 turris pppd[15467]: RP-PPPoE plugin version 3.8p compiled against pppd 2.4.7
Jun 21 14:05:13 turris pppd[15467]: pppd 2.4.7 started by root, uid 0
Jun 21 14:05:13 turris pppd[15467]: PPP session is 53848
we can see that the real sleep time is reported two times, I’m going to lower it down to see it behaves better.