Hello,
Im new here and Im using the Turris Omnia since one week (more or less).
I think that I have the same issue and at first I try to get support in the OpenWRT forum.
I want to paste the link from the thread in this forum here instead to write the fully thread again (I hope it is ok).
I`m so angry about this issue.
I need a stable internet connection (actually are working in the home office and sure the family are sitting in my neck).
If I have no chance to fix this issue in an short time than I must switch to another router … so sorry to say this!
See the thread in OpenWRT forum: Forced separation of internet connection => Solution for …
I hope you can bring the solution 
It may require some effort your end to get to the bottom of it - providing some verbose debugging logs about the involved processes - pppd | netifd - as suggested in the other thread.
It is not likely being an issue caused by router hardware but rather a bug in the OS; it could even be some sort of misconfiguration on the ISP end - unless you have another spare router that does not exhibit the issue (like the FritzBox you mentioned?)
The common denominator with the original post seem to be:
- FTTH with PPPoE authentication and IPCP for dynamic IPv4 provisioning (instead of less intrusive DHCPv4)
- IP rollover every 24 hours
Maybe it is even the same ISP as for @fantomas (none been disclosed so far), but probably not - from the @fantomas log it looks like an ISP in Slovenia whilst you seem based in Germany.
The last Router from the ISP was an FritzBox 7490.
They are use one setting to separate the connection in the night.
Maybe this will be the reason why I don’t observed the issue.
Is there a work around possible like a cronjob who reboot the router?
It is not going to help as demonstrated in other thread because either way the reconnection attempt fails, same as reported initially in this thread. The root cause is not clear and would require some debugging effort unfortunately.
One thing you could try, though it would be surprising if it cures the issue
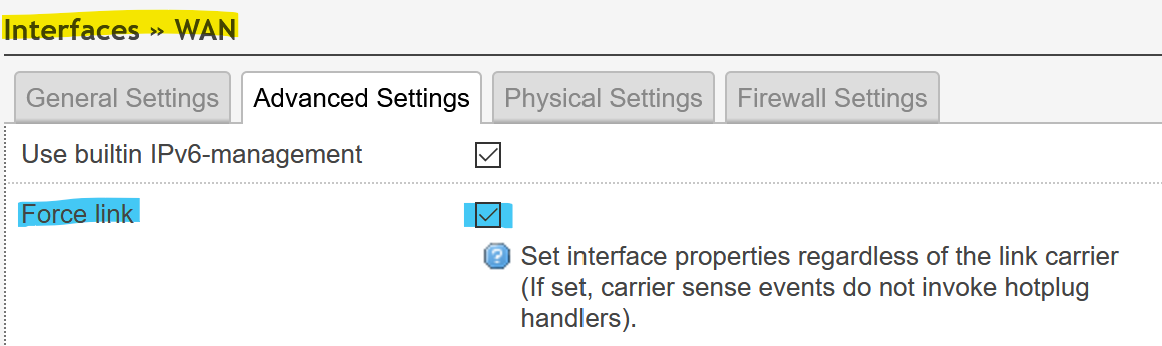
via LuCI
After set and applied in LuCI then from the ssh cli service network restart ; logread -f and see if the connections gets re-established or still fails.
I setup the option Force link and push Set & applied. After that I done service networtk restart on the SSH cli and see what happened under logread -f:
root@turris:~# service network restart
‘radio0’ is disabled
‘radio1’ is disabled
root@turris:~# logread -f
May 27 15:49:08 turris netifd: Interface ‘wan6’ is enabled
May 27 15:49:08 turris netifd: Network alias ‘pppoe-wan’ link is up
May 27 15:49:08 turris netifd: Interface ‘wan6’ has link connectivity
May 27 15:49:08 turris netifd: Interface ‘wan6’ is setting up now
May 27 15:49:08 turris netifd: Interface ‘wan’ is now up
May 27 15:49:08 turris firewall: Reloading firewall due to ifup of wan (pppoe-wan)
May 27 15:49:10 turris firewall: Reloading firewall due to ifupdate of wan (pppoe-wan)
May 27 15:49:12 turris netifd: Interface ‘wan6’ is now up
May 27 15:49:12 turris firewall: Reloading firewall due to ifup of wan6 (pppoe-wan)
May 27 15:49:13 turris odhcpd[2879]: A default route is present but there is no public prefix on br-lan thus we don’t announce a default route!
May 27 15:49:22 turris kresd[9873]: [ ta ] key: 20326 state: Valid
May 27 15:49:22 turris kresd[9873]: [ ta ] next refresh for . in 10.465694444444 hours
May 27 15:50:01 turris /usr/sbin/cron[10021]: (root) CMD (/usr/bin/notifier)
May 27 15:50:01 turris /usr/sbin/cron[10022]: (root) CMD (/usr/bin/rainbow_button_sync.sh)
May 27 15:51:01 turris /usr/sbin/cron[10136]: (root) CMD (/usr/bin/rainbow_button_sync.sh)
May 27 15:52:01 turris /usr/sbin/cron[10224]: (root) CMD (/usr/bin/rainbow_button_sync.sh)
This is the first time when I do not must reboot the router to reconect.
My issue was happened 15 min. before and this is reproducible every evenein between 17 - 19 o`clock german time.
What does it means May 27 15:49:22 turris kresd[9873]: [ ta ] next refresh for . in 10.465694444444 hours?
I will see what is happened tomorrow on the same time.
unrelated to this thread/issue. Is some log output from kresd, the local resolver instance that ships with TOS.
I don`t know what it means.
For me is not clear it was successful yes or no.
Tomorrow evening I will see it was yes/no.
But what means
…next refresh for . in 10.465694444444 hours
[ ta ] = trust anchor
next refresh = according to https://tools.ietf.org/html/rfc5011.html
If you have further questions about kresd there is https://knot-resolver.readthedocs.io/en/stable/ or else perhaps open another thread in the forum
OK mrs.crox,
thanks a lot but for me it`s not clear will be successful this action yes or no?
Sure, tomorrow I will observe …
It looks promising considering
Well,2 years ago when the MOX arrived it took me ( nOOb) a few days to find this out, since my ftth<>pppoe had continous drops, and errors. I had or to reboot the Mox, or disconnect from the fiber-modem and reconnect again. After i did [force link] X ( no clue, just tried it ) no problems anymore in the whole WAN part.
Somehow the WAN<>FTU-LAN have some sort of communication problems, Not a clue about the technical side.
With my Omnia the WAN goes to cable modem, and there zero issues on that part. So i think it def has to do with the FTU talking to the WAN ( mox, omnia )
Sounds brilliant and I hope strongly it will works.
I like the Turris Omnia from the beginning and I like the idea behing.
I would like to see how big is the performance of this HW and I want to have a lot of fun.
Im confident its very good Router …
By the side: Do you have seen in the OpenWRT forum how the cancelled my thread when they realized that my HW is a Turris router? Unbelivable or what is there in the backround? Is there a reason for this unfriendly conduct?
netifd is supervising pppd and I trust that netifd is somewhat struggling at times with the carrier link state of the WAN port (ethX).
With TOS, that you mentioned in the OpenWrt forum, you are using a patched version of OpenWrt and the OpenWrt forum supports OpenWrt and not TOS. Those rendering support in the OpenWrt forum are not familiar with the patched code in TOS.
I didn’t know if they are related so I didn’t filter them out.
I plan to go HBT, I just waited for some info in other threads
the number is increasing by one each time. Yesterday, it took very long to reconnect. I posted first and last attempt. Logs from second and third attempt were quite the same (different order of some lines and magic numbers)
root 8730 0.0 0.0 1040 756 ? S May26 0:06 /usr/sbin/pppd nodetach ipparam wan ifname pppoe-wan lcp-echo-interval 1 lcp-echo-failure 5 lcp-echo-adaptive nodefaultroute usepeerdns maxfail 1 user XXX password YYY ip-up-script /lib/netifd/ppp-up ipv6-up-script /lib/netifd/ppp6-up ip-down-script /lib/netifd/ppp-down ipv6-down-script /lib/netifd/ppp-down mtu 1492 mru 1492 plugin rp-pppoe.so nic-eth2 debug kdebug 7
Might be nothing but somewhat the incrementing channel number does not seem healthy. But I am not familiar whether the local pppd session is causing this, since it should not, or the remote end from the ISP.
Anyway, try the above force_link workaround and see whether it cures your case as well.
If force_link will be a workaround which works than it’ s fine for me.
Will be fixed in Version 5 than perfect!
i have set force_link and will report if that helps
set up and tell us. if it works for day or two, great. you can tell then in openwrt forum too
Hi,
today it has works fine w/o any interrupt of losing connection.
Tomorrow I will reflash the router (tip from Turris support regarding another issue, doesn’t related to this issue).
After that I will use the same settings and than I will report again.
Today was fine but I will see …
So that part is how OpenWrt wants to handle reconnects, instead of letting pppd (and each other protocol handler) manage retries in its own way, the goal (if I understood correctly) is to move that logic into netfid, see:
https://forum.openwrt.org/t/ppp-duplicate-maxfail-process-option/65092/2?u=moeller0
“Yes, since netifd is supervising pppd, we don’t want pppd to continue trying on connection failures. We want to notify netifd and terminate pppd so that netifd can restart the process as needed.”
That should “solve” the SIGTERM subthread, while inconveniently helping not with the real underlaying issue.